
MySQL简单总结
条件查找
1 | select * from dataAnalyst |
1 | select * from dataAnalyst |
模糊查找
1 | select * from dataAnalyst |
Groupby
1 | select city from dataAnalyst |
1 | select city,count(positionId) from dataAnalyst |
去重复——DISTINCT
1 | select city,count(positionId),count(distinct companyId) from dataAnalyst |
1 | select city,education,count(1) from dataAnalyst |
Having
1 | # having 就是对groupby进行过滤的 |
Like
1 | # 获取字段含有“电子商务”的用like |
count if
1 | # 这里只输出城市(嵌套查询) |
不同城市下面电商占这个城市的招聘人数的占比并过滤大于10
1 | select city,count(1), |
优雅的写法——As
1 | select city,count(1), |
SQL函数
left和locate和right
1 | select left(salary,locate('k',salary)-1),salary from dataAnalyst |

1 | select |
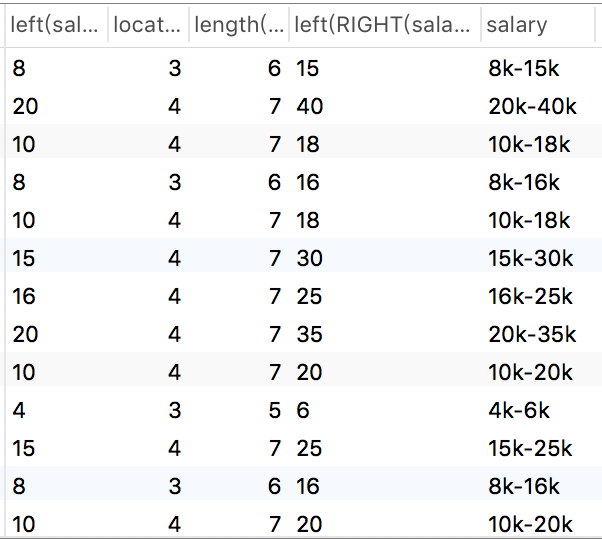
substr
substr(字符串,从哪里开始,截取长度)
1 | select |
子查询
基于查询结果的查询,嵌套查询
1 | select (bottom + top)/2 from( |

分组——case when
主要用来数据清洗
1 | select |

过滤——where in
1 | select * from dataAnalyst |
多表聚合查询——Join
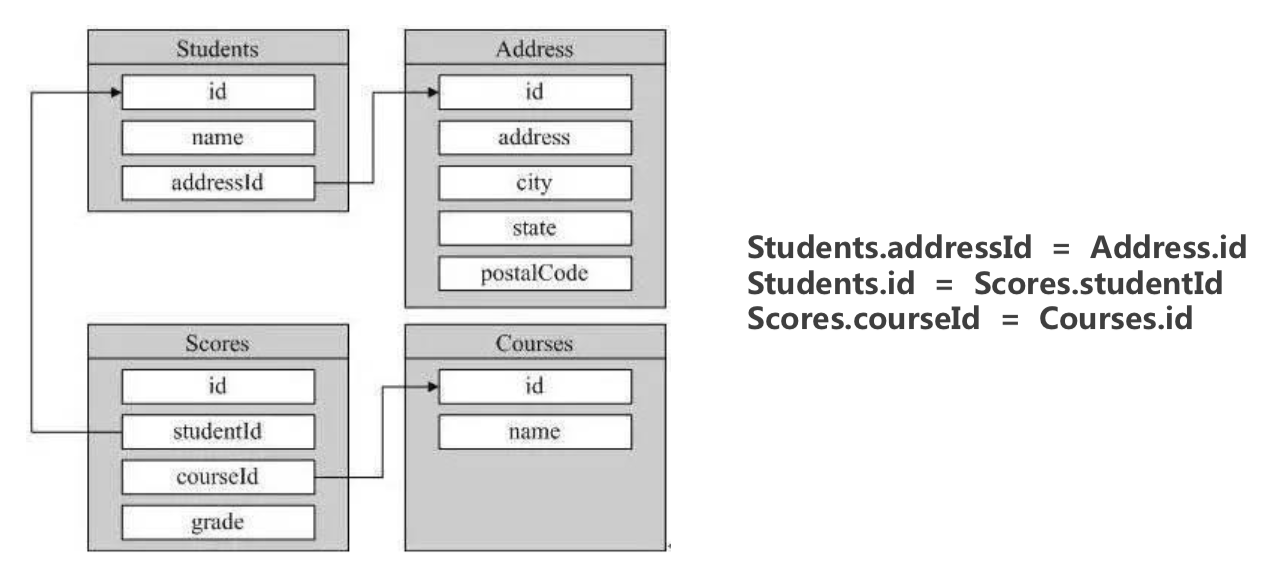
某一个公司招聘职位,在另一个表中查找信息
1 | select * from dataAnalyst |
连结两张表
1 | select * from dataAnalyst ❌ |
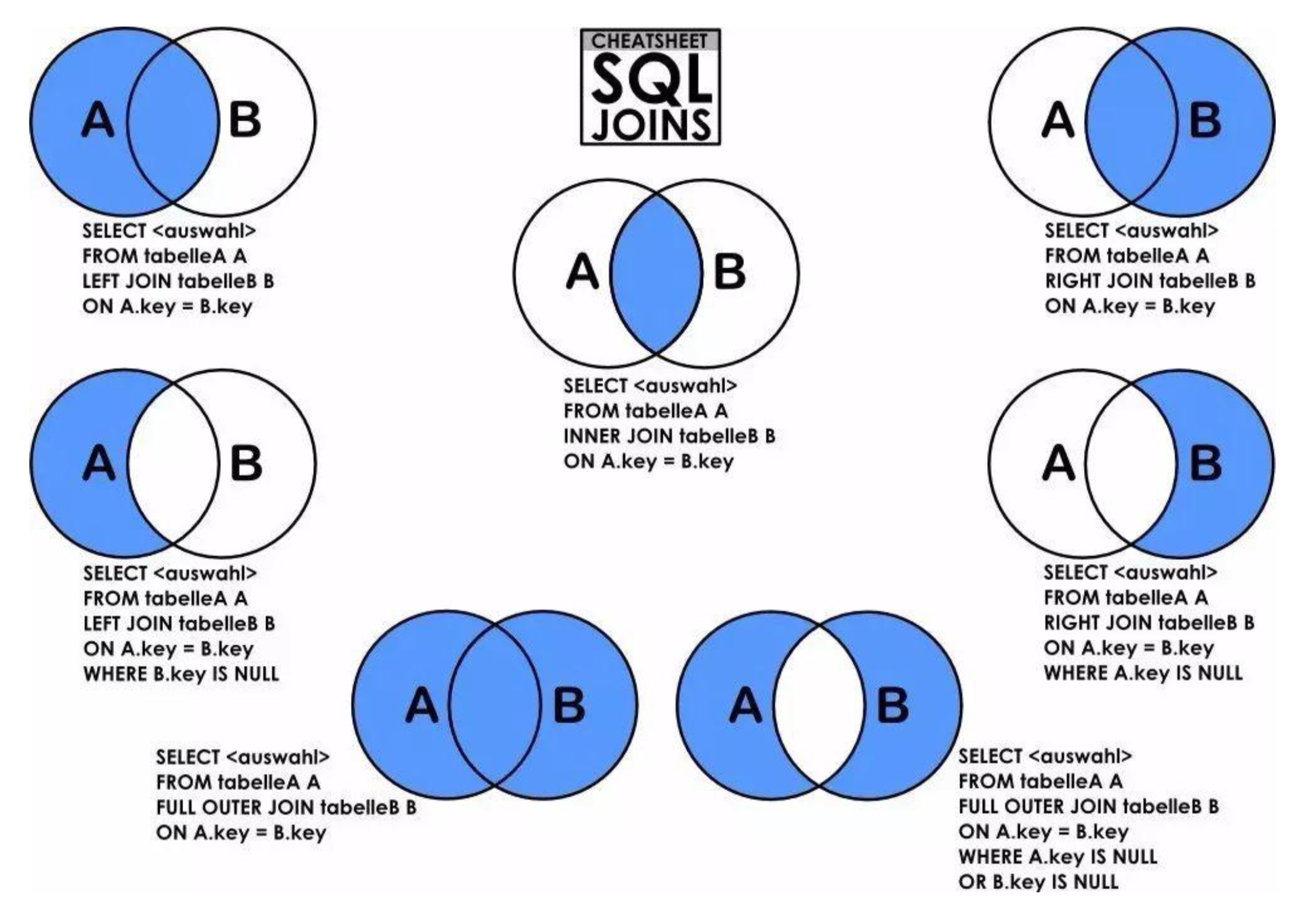
左连接
保留左边,右边硬凑,没有就null
1 | select * from dataAnalyst as d |
join就是取交集,left join就是A是全部B是部分
1 | # 排除法统计 |
150-500人的占比
1 | select count(1),count(t.companyId),count(t.companyId)/count(1) from dataAnalyst as d |
LeetCode——训练刷题
时间
1 | select now() |
1 | select |
练习题
统计不同月份的下单人数
统计用户三月份的回购率和复购率
统计男女用户的消费频次是否有差异
统计多次消费的用户,第一次和最后一次消费间隔是多少?
统计不同年龄段,用户的消费金额是否有差异?
统计消费的二八法则,消费的top20%用户,贡献了多少额度
统计不同月份的下单人数
1 | select month(paidTime),count(distinct userId) |
统计用户三月份的回购率和复购率
1 | # 统计用户三月份的复购率 |
不是很好的方法:
1 | # 统计用户三月份的回购率 |
首先查找出userId在每个月份的支付情况
1 | select userId,date_format(paidTime,'%Y-%m') as m from orderinfo |
然后左连接两张相同的表:
1 | select * from( |
此时得到的是两张表的笛卡尔积(左连接非唯一字段,是局部笛卡尔积。)

然后增加条件筛选,此时添加了非唯一条件,笛卡尔积自动去除
1 | 可以统计所有的月份: |

统计男女用户的消费频次是否有差异
平均数
1 | select sex,avg(ct) from ( |
统计多次消费的用户,第一次和最后一次消费间隔是多少?
1 | select userId,datediff(max(paidTime),min(paidTime)) from orderinfo |
统计不同年龄段,用户的消费金额是否有差异?
年龄除10然后取整数
1 | select o.userId,age,count(o.userId) from orderinfo o |
平均数
1 | select age,avg(ct) from ( |
统计消费的二八法则,消费的top20%用户,贡献了多少额度
先统计总人数
1 | select count(userId)*0.2 from( |
统计贡献
1 | select count(userId),sum(total) from( |
SQL连接PowerBI