毕业设计进展报告五——陶家成
一周主要工作内容
- 了解特征提取的过程
- 了解MFCC及其实现原理
- 了解HMM
- 打了一些codeforces的题
- 《语音信号处理》、《Automatic Speech Recognition》
未完成:
- 了解傅立叶变换及其在深度学习中的应用
具体内容
关于音频特征MFCC提取
MFCC概述
根据人耳听觉机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度。所以,人们从低频到高频这一段频带内按临界带宽的大小由密到疏安排一组带通滤波器,对输入信号进行滤波。将每个带通滤波器输出的信号能量作为信号的基本特征,对此特征经过进一步处理后就可以作为语音的输入特征。由于这种特征不依赖于信号的性质,对输入信号不做任何的假设和限制,又利用了听觉模型的研究成果。因此,这种参数比基于声道模型的LPCC相比具有更好的鲁邦性,更符合人耳的听觉特性,而且当信噪比降低时仍然具有较好的识别性能。
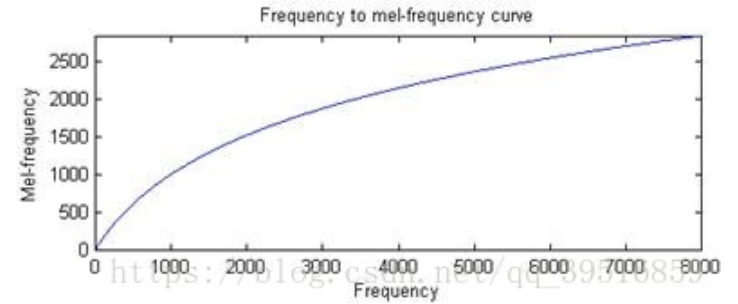
梅尔倒谱系数是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率的非线性特性,它与频率的关系可用下式近似表示:
$Mel(f) = 2595 · lg(1 + f/700)$
Mel频率与线性频率的关系:
MFCC特征提取过程包括

- 对音频信号预加重、分帧和加窗
- FFT(快速傅里叶变换)得到频谱
- 频谱通过Mel滤波器组得到Mel频谱
- 在Mel频谱上面进行倒谱分析得到MFCC特征
通过这个MFCC特征提取过程,语音就可以通过一系列的倒谱向量来描述了,每个向量就是每帧的MFCC特征向量。语音识别系统就可以接着在MFCC特征的基础上进行训练和识别了。
预加重
预加重的目的是提升高频部分,对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。原因是因为对于语音信号来说,语音的低频段能量较大,能量主要分布在低频段,语音的功率谱密度随频率的增高而下降,这样,鉴频器输出就会高频段的输出信噪比明显下降,从而导致高频传输衰弱,使高频传输困难,这对信号的质量会带来很大的影响。因此,在传输之前把信号的高频部分进行加重,然后接收端再去重,能够提高信号传输质量。
预加重相当于图片处理中的灰度拉伸/二值化,「增加识别的准确性」
预加重其实是将语音信号通过一个高通滤波器:
$x_p(n) = x(n) - k·(n-1)$ (任取k,但是语音处理通常用0.9-0.97)
分帧
语音信号的变化是非常迅速的,但是通常傅里叶变换适用于分析平稳的信号。我们假设在较短的时间跨度范围内,语音信号的变换是平坦的,一般取这个时间跨度为20ms-40ms。为什么取这个范围呢,因为能够保证一帧内既有足够多的周期,又不会变化太剧烈。
为了「分离平滑帧」
加窗
每帧信号通常要与一个平滑的窗函数相乘,让帧两端平滑地衰减到零,这样可以降低傅里叶变换后旁瓣的强度,取得更高质量的频谱。对每一帧,选择一个窗函数,窗函数的宽度就是帧长。常用的窗函数有矩形窗、汉明窗、汉宁窗、高斯窗等。
为了「取得更高质量的频谱」
假设分帧后的信号为S(n), n=0,1…,N-1, N为帧的大小,那么乘上汉明窗
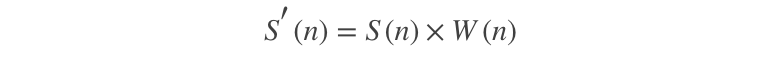
后,W(n)的形式如下:
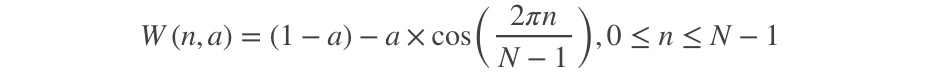
FFT(快速傅立叶变换)
由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。所以在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。
得到「频谱的能量分布」
对语音信号频谱取模平方得到语音信号谱线能量。
声谱图「重点部分」
声谱图的作用:
- 音素以及它们的属性更易于观察
- 通过观察共振峰和它们的转变可以更好的识别声音
- 隐马尔科夫模型就是隐含地对声谱图进行建模以达到好的识别性能
- 能够直观的评估TTS系统(text to speech)的好坏,直接对比合成的语音和自然的语音声谱图的匹配度即可
经过前面的预处理,每帧语音都对应一个频谱。
「但是这部分还是看不太懂」
计算通过Mel滤波器的能量
将能量谱通过一组Mel尺度的三角形滤波器组,定义一个有M个滤波器的滤波器组(滤波器的个数和临界带的个数相近),采用的滤波器为三角滤波器,中心频率为f(m) 。M通常取22-26。各f(m)之间的间隔随着m值的减小而缩小,随着m值的增大而增宽,如图所示:
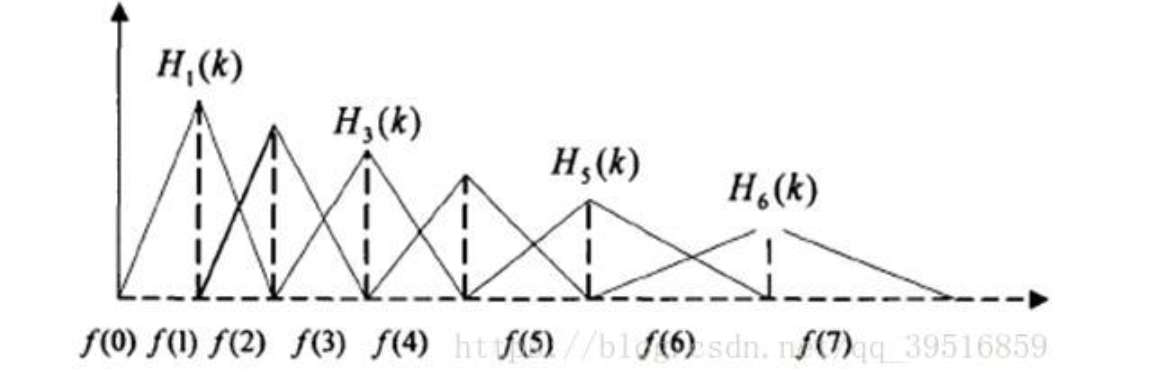
对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。(因此一段语音的音调或音高,是不会呈现在MFCC 参数内,换句话说,以MFCC 为特征的语音辨识系统,并不会受到输入语音的音调不同而有所影响)此外,还可以降低运算量。
三角滤波器的频率响应定义为:
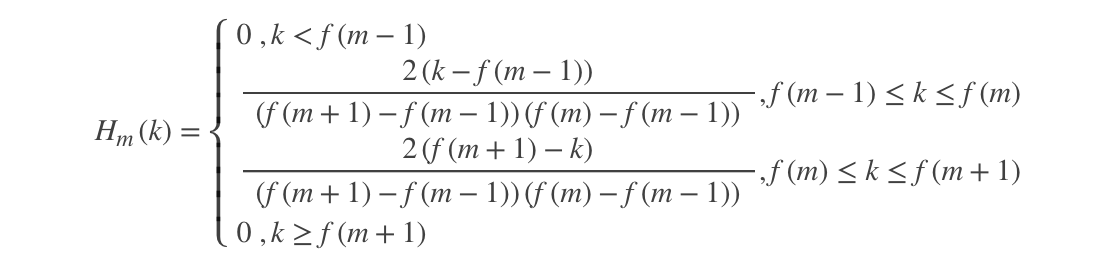
计算每个滤波器组输出的对数能量为 :
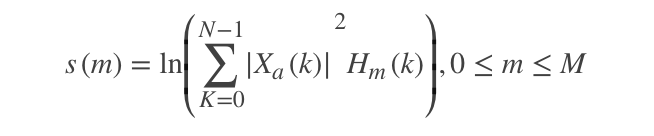
计算DCT倒谱
经离散余弦变换(DCT)得到MFCC系数 :
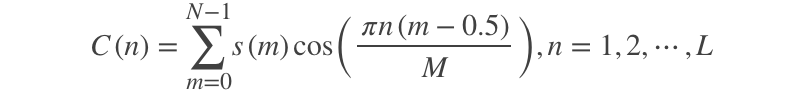
将上述的对数能量带入离散余弦变换,求出L阶的Mel参数。L阶指MFCC系数阶数,通常取12-16。这里M是三角滤波器个数。
在六大区实现的官方源码中使用HTK实现MFCC和HMM
整个HTK是使用HMM作为语音识别的核心,当HMM应用于孤立词语音识别时,它用不同的隐含状态来描述不同的语音发音,对于连续语音识别系统,多个孤立词HMM子模型按一定的语言模型组成的复合HMM模型序列来刻画连续的语音信号,在序列中每个模型直接对应于相关的发音,并且每一个模型都有进入和退出状态,这两个状态没有对应的观察矢量,只用于不同模型的连接。
HTK是英国剑桥大学开发的一套基于C语言的隐马尔科夫模型工具箱,主要应用于语音识别、语音合成的研究,也被用在其他领域,如字符识别和DNA排序等。HTK是重量级的HMM版本。
代码位置:
inferenceLSTM/read_data和inferenceLSTM/HTKfile
HTK文件结构:
帧数:4字节(第0-第3字节)
采样周期:4字节(第4-第7字节)
每一帧的字节数:2字节(第8-第9字节)
参数类型:2字节(第10-第11字节)
数据:N字节(第12字节开始-文件结尾)
TODO
- 把文件中的主要代码和预处理脚本都理清看懂
- 完成采集数据集的准备工作,弄清音频的要求
- 弄懂声谱图部分,性能调优的方向之一
- 看书《深度学习中文版》
- 第三章——概率与信息论
- 第八章——深度模型中的优化
- 第十章——循环和递归网络——LSTM
- 学好算法,打打codeforces
ADD
- 了解傅立叶变换及其在深度学习中的应用